

课程介绍
除了可靠性之外,Kafka 另一个特点就是吞吐量大,而且是高并发场景的首选消息队列。那么Kafka 到底是如何做到的呢?
这一期就带着你把 Kafka 这些高吞吐的设计要点都过一下,只要你能把这些要点搞明白,那么你就会对 Kafka 高吞吐相关的参数配置有更深入的了解,同时还会学到一些高性能的设计方法以及操作系统底层的工作模式,帮助你更高效地设计出一个高吞吐的系统。
课程目录
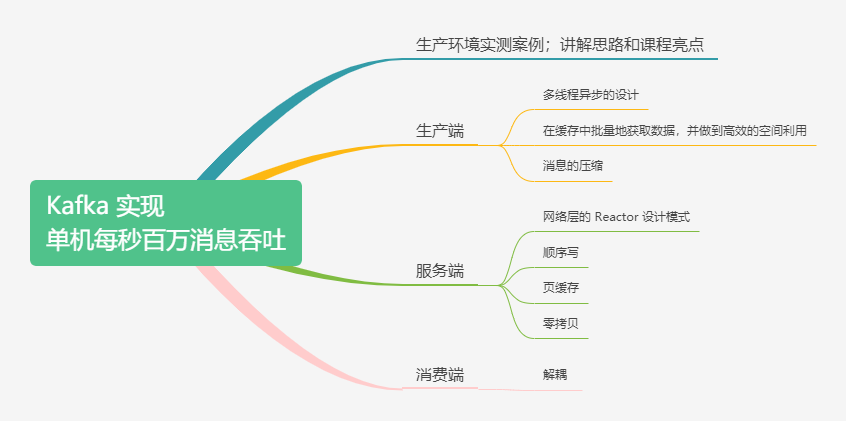
主题背景和意义
生产端
多线程异步的设计
在缓存中批量地获取数据,并做到高效的空间利用
消息的压缩
服务端
网络层的 Reactor 设计模式
顺序写
页缓存
零拷贝
消费端
总结
课程核心
讲师介绍
陈阳,前京东集团架构师
10年+互联网一线开发经验,曾在京东、美团等多家互联网大厂任职,负责过公司站内搜索引擎设计与搭建、智能支付系统稳定性工作、消息队列设计开发工作等,参与公司多款中间件开发,深入研究并改造过多种开源产品的实现,在架构设计方面经验丰富。与此同时,还负责开发团队的建设与人才梯队的培养。